
LRR Survey 3 results are here!
I've recently released Version 0.8.0 "Black Tie White Noise", which is mostly a polish release this time instead of a big bowl o' features.
This makes for a nice, clean slate, and the 0.9.x development cycle should therefore mostly be driven by your suggestions -- Downloader support was the last "personal" feature I really wanted in.
So let's get to analyzing those results!
Users and platforms
| Operating System | 2020 Users | 2021 Users |
|---|---|---|
| Windows | 31 | 45 |
| Linux | 29 | 72 |
| macOS | 4 | 2 |
| DSM | 1 | 4 |
| Unraid | 1 | 3 |
| Doesn't actually use LRR | 4 | 3 |
| Total | 70 | 129 |
Lots more replies this year -- I think actually advertising the survey properly yielded some results! 😅
| Install method/location | 2020 Users | 2021 Users |
|---|---|---|
| Windows Installer - Server | 2 | 4 |
| Windows Installer - Local | 29 | 37 |
| Docker - Server | 21 | 67 |
| Docker - Local | 5 | 7 |
| Built it from source - Server | 6 | 7 |
| Built it from source - Local | 2 | 2 |
| Homebrew | 1 | 0 |
| UnRAID Package | N/A | 2 |
| Total | 66 | 126 |
Nothing too surprising here.
The UnRAID package is technically a glorified Docker container(just like the Windows installer lmao), but I thought it'd be interesting to count it separately.
Last year I was impressed at the Github star count being at 250, but somehow now it's at 600+?? Please stop botting the starcount I can't believe there are that many people
Usage and external readers
Favorite features
The original question for this was "Which of the following features do you use most/care the most about?"
| Feature | Users |
|---|---|
| Batch Tagging | 85 |
| Categories | 72 |
| URL Downloading | 55 |
| Column Customization | 44 |
| Backup/Restore | 38 |
| Client API | 34 |
| Compact/Table View | 30 |
| Custom Themes | 12 |
Some of those are not surprising at all (Batch Tagging is always a hit and I should probably expand it a bit in the future), but I'm glad people enjoy column customization!
Its current implementation in thumbnail view is a bit weird, but it works.
I've really enjoyed using URL Downloading (especially since building the Tsukihi Browser Extension), so I'm glad it's been of use to others as well.
Themes
| Theme | Users |
|---|---|
| Default | 83 |
| Sad Panda | 29 |
| HentaiVerse | 3 |
| Nadeko | 5 |
| Yotsugi | 3 |
| Custom | 2 |
| Total | 126 |
That one kinda came out of left field since I was somehow expecting themes to be used more. (despite never having ran a survey for it 🥲)
The current custom-CSS-dropdown system is one of the oldest pieces of code in the app, but it's not very well exposed. (just being a small link at the footer of every page).
I'm likely going to move theme selection into settings and try to expose it better. And if that doesn't work I'll just gut themes maintaining 5 CSS files is painful
Third-party clients
| External Readers used | 2020 Users | 2021 Users |
|---|---|---|
| No, I only use the Web Reader | 49 | 37 |
| Tachiyomi Extension | 11 | 59 |
| Ichaival (Android) | 7 | 22 |
| LRReader (Windows) | 3 | 28 |
| Generic OPDS | 0 | 4 |
| DuManga (iOS) | N/A | 9 |
| Tsukihi (WebExtension) | N/A | 21 |
It's great to see more people use the third-party clients!
There's a fair amount of work involved in them, and I'd never have thought there'd be a client for every major OS somehow.
I also suspect they're used way more than this survey lets on due to, ahem, external services reimplementing the LRR API to distribute manga without having to expose an HTML front-end.
Which I think is awesome! Although said services should probably implement the API properly to avoid a bad user-experience.
I'm planning to add links to all third-party clients in the main app when I finally get around to implementing a good out-of-box wizard, so hopefully users will notice said clients even more in the future. 🙏
Feature requests and suggestions
The Featurebowl
| Feature | Wished by |
|---|---|
| Improved Reader Performance | 64 |
| Improved Search Performance | 64 |
| Duplicate Detection | 62 |
| Deeper Category Integration | 35 |
| Better Out of Box Experience | 21 |
Yeah, I pretty much rigged the results by adding those two improved performance choices at the top. 🎰
I have some stuff in the works for Reader performance, and Search has been slightly improved in 0.8, although there's still a bunch of work to be made here.
Dupe detection is still a favorite, and I'm sorry for not having worked on it this year 🥲 However LRReader now has a deduplicator available, and it works quite well!
A built-in implementation would only be marginally faster, so I'm probably going to redirect people to use LRReader for this for the time being. (And someday I'll sherlock it I guess)
And uh here's a direct quote from last year:
I still want to do the OoB experience thing at some point, it's logical that existing users wouldn't care too much about it.
Suggestion Box
Here are a few interesting messages/reqs I got from the feature suggestion box.
👉 Situational compression/Compression options like on sadpanda.
This feature isn't advertised too well but does exist -- Check "Resize Images in Reader" under Global Settings.
If you think it's not as powerful/efficient as you'd like, a GH Issue would be most welcome!
👉 Somekind of way to check whether X gallery on panda is already on the server. Example: You load the page and somewhere in the metadata of the gallery it's writte it's not currently uploaded on the LRR server.
Please check out the Tsukihi Browser Extension for this!
👉 Also a watched folder that auto-imports.
The content folder normally auto-imports whatever lands in it and that essentially just works for your case (Linux/Docker user), if it's not importing properly I'd recommend checking if the background worker is running.
👉 Wish there's a way to disable or pause background worker Shinobu, maybe start checking new files manually is better way for my poor hdd, they always been reading and cannot go sleep mode.
There are API Endpoints to stop/start Shinobu, but I haven't made them accessible in the main interface since I really don't think users should run with the worker off.
LRReader does provide the option though if you really want to do it
Your HDD woes might've been caused by Redis writing to disk a bit too often since I've made Minion use it as a database instead of SQLite -- I've changed the Docker/Windows Redis config in 0.8.0 to write to disk much less often, so hopefully this won't be an issue anymore. 👍
👉 custom rules to merge and replace redundant tags, select and delete multiple archives at once
👉 A feature to scour the database and replace all tags reading 'x' with a 'y' equiv would be fantastic.
👉 Tag replacement
Tag Rules, recently added in 0.8.0, should cover those requests pretty well! There's no support yet for going back and applying them across the entire database, but I'll try adding that in a future release.
👉 Better batch tagging (tag merging/renaming, mostly for dealing with author names) (also a list of all tags would be awesome)
👉 feature to help edit tags of multiple manga/doujin at once
👉 Checkboxes or ability to select mutiple files at once (for batch deletion or adding to categories).
👉 batch tagging in minion, change job delay according to service response (avoid panda bans)
I'm considering expanding on batch tagging, so stuff like batch deletion is certainly on the table.
Now that I'm thinking of it, it'd also be a convenient place to integrate tag rules, so you can apply them across multiple files in one click.
I probably won't move batch tagging to Minion however, since the current implementation using websockets allows one to easily monitor the state of the batch operation from the browser. (At the expanse of having to keep the browser tab open, I know)
👉 Clickable tags in the tag cloud and some way to filter out meta tags like "translated" and "language" from it.
👉 Infinite scrolling for double page mode and a tags index page with counts.
I'm planning to expand the tag cloud to also include a list of all tags and their count -- The data already exists so it's a waste to not expose it better.
👉 Put reading behind a password please. My instance is publicly accessible under my domain name, but I don't want other people reading it.
Please check the Documentation.
👉 Edit gallery metadata while reading. Also add to certain category while reading.
You can already add stuff to a category within the reader, but metadata edition is indeed lacking. I'm not sure how to integrate it properly at the time however. 🤔
👉 show archive tags/page overview by default instead of 1st page
👉 I'm the guy who was asking for more of an EH style gallery view during the last survey with the tags on top and thumbnails below without it going directly in to the full image reader view.
This has been asked a few times already so I'm prooobably going to make it an option, the main blocker with this is that I'll have to add incremental loading of some sort to the gallery overlay so it doesn't fire a billion API calls for each page as it pops up.
👉 Random based on current search
👉 Random button that uses entries from the search query
👉 Random Order for searchs
👉 Random archive adhere the currently chosen categories and filters.
👉 A nice feature to add is random gallery button matching the current search or random gallery inside a category, which open the random gallery in a new tab.
👉 Random archive "list" at home(index) page
god okay okay I get it
I've been thinking about overhauling the index page for a while now by adding some form of carousel views, similar to what Plex and others do:
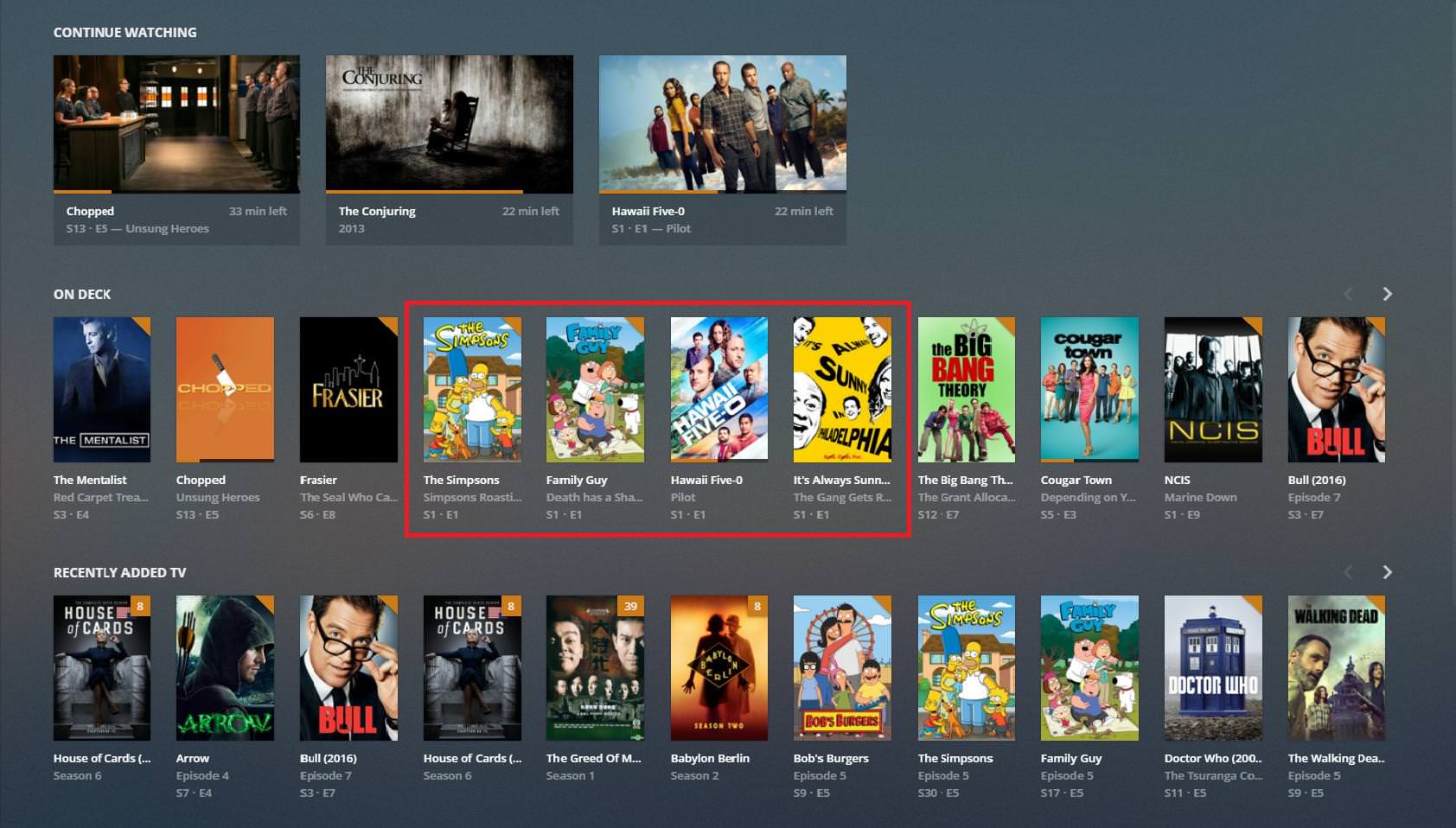
I'll likely make one of these carousels contain random archives based on the current search filters.
In the future, I might even make the current index view secondary, and have the landing page be a bunch of carousels like Komga does -- We'll see.
👉 i guess since downloader additions are plugins this is maybe not the best place to ask, but i'd like a pixiv downloader since some artists will re-up their older doujins onto pixiv a while after they go out of print.
👉 We need more download options. Please, add nhentai one.
While the LRR downloader plugin structure allows for basically anything, it gets annoying real fast to write downloaders for websites that don't offer a straight .zip download link.
Go yell at nH to provide real download links for their downsampled content. 🤷♂️
External tools like gallery-dl already do the whole scrape-and-download dance, so I don't fancy reinventing the wheel here.
(Although as always, I'm open to external contributions. 😇)
I recall that Pixiv is particularly annoying to maintain a scraper for due to the whole thing constantly changing and requiring a bunch of cookies...
👉 backup database currently times out on large libraries (mine is at 8723), and also being able to delete archive without the library view refreshing
👉 Deleting a file without going back to the home (no url change).
👉 Persistent Search in order to make the deletion of unnecessary files easier
This is tracked here. I'll try prioritizing it since it's not too hard.
👉 An option to have the "date uploaded" (different from the "date added" that is present already) data visible and ability to sort by it.
👉 Option to make sorting by date_added default
👉 Ability to show the date_added as human readable instead of Unix timestamp
👉 I suggest adding a newest gallery sort and a history section.
I'm planning to (finally) make date_added a default feature, but it'll only use the time the file was scanned by the server -- For stuff like last modified time, you'll have to keep relying on the existing plugin.
👉 fixing ordering issues from the web interface (e.g. cases where the cover is alphabetically not the first image in the zip file)
This is actually kinda difficult; I experimented once with using natural sort instead of alphabetical to figure out the cover image, but it introduced more problems than anything.
Maybe a simple "set this image as the cover thumbnail" option in the reader would be enough to catch the few edge cases where the cover isn't the first image. 🤔
👉 Plugin support for other sites, specially sites that host mostly western content and provide metadata information.
👉 more non-h related features e.g. retrieving artist/genre/etc. from anilist
I've quickly looked at the comicvine API and might integrate in a plugin further down the line. No real promises for now tho!
👉 Renaming & sorting the comic files based on scraped info. Sort of similar to how iTunes handles files.
👉 saving metadata inside or alongside the archive
My policy for user content is to not touch it in any way since that usually annoys people more than anything, but this stuff could be doable through script/tool plugins.
Similarly, saving metadata files next to the zips would break users who set their content folder as read-only.
👉 nHentai theme
👉 More UI customization
How dare you ask for more themes after those survey results.
Utterly unforgivable.
I don't plan on introducing more themes since 5 is already a lot to maintain
👉 Also not essential but would adding a column with the number of pages or file size be possible??
👉 More columns to sort homepage
Adding columns to the index, while possible, is very painful since DataTables is awful to work with and I hate it, so it's probably not in the cards for the time being.
👉 fully support wsl2, forwarding ip
go yell at microsoft, bridge mode in wsl2 is...not very convenient we'll say.
👉 Similiar Doujin Recommendation when done with one
👉 Some sort of Similarity search, for example recommendations based on tag similarity for a currently viewed gallery.
This is interesting and I wouldn't mind adding it, although I'm not sure how to best calculate tag similarity. (And it'd probably require me to make actual tag indexes in the database but I think I'll have to do that for search speed nonetheless)
I'll make a note of it.
👉 going back from a reader view the library position should be remembered
👉 A feature to not immediately go back to the first page of the site when leaving the reader. Like maybe go to the page you were on before opening the reader.
👉 more persistence on archive page. For example, if I toggled "new archives only", when I press the "return" button after reading, the filter should still be there.
You can technically use your browser history to do that, since search parameters are now saved in the URL.
Past that, I suppose this could be solved by putting your last search in localStorage and serving it back when you open the index again -- Food for thought.
👉 A better series integration. Having categories for every composite tank is cumbersome. Being able to create a faux archive of galleries to create a searchable meta-tank would be great.
👉 Better implementation for normal manga series that expanding volumes and so on.
👉 bookmark pages, chapter separation (mainly for tankoubon/anthology), better user friendliness for archive status (new/completed etc.)
I've been thinking about adding "Meta-Archives" that batch multiple IDs under one element and are shown as such, but I didn't want to introduce too much complexity and confusion with Categories.
Although I'm seeing komga has both tanks and simili-categories, so it might be fine?
👉 Of all the more unusual features I may suggest, being able to have a more piecemeal "no fun mode" setting (like being able to hide certain archives in a category or ones that say have a certain tag) would be very useful.
👉 I think you have mentioned that you don't want multiple user accounts. I think if there was a way to just have account roles or tag blacklists is what prevents me from using LANraragi full time, and instead I also run Komga on my unraid, using the docker setup.
While I'm still not too keen on multiple user accounts(mostly because it'd be a fair amount of work and I don't think most users want/need those), I could add whitelisted categories that'd be accessible even with no-fun on. Lemme know if that's something you want!
👉 Automatic status/tag for Reading, Completed manga/doujin. The ability to filter these (show only unread, reading, etc.). The ability to edit this using right-click on the manga/doujin (right-click on manga -> Mark as Read / Unread).
👉 It's something pretty simple but I'd just like to have a mark as read/unread button, I've still not managed to find that if it exists.
I'm considering adding inbox/archive functionality ala Hydrus, since I personnally have a few "To Read" categories already and it probably warrants bring more tightly integrated.
Follow this issue to keep tabs on this!
Closing thoughts
There were way more replies this year compared to last time, but I hope I caught most of the major requests here!
I don't work as much on LRR as I did in the past as I'm trying to get other projects off the ground, but for the time being, as long as I'm using it it's certainly not dead. 👏
If you want to ask something else or just yell because I totally misinterpreted what you were saying, there's always the Discord, Github Discussions, and the comments of this very post.
Thanks for reading all the way to the end and supporting the project!
I can't copy all the kind words I got from the survey here lest I bloat the article by another 100 lines, but know that it's all very much appreciated. 🥲

